
The AI Capability Matrix
A framework for getting AI POCs to production

One of the key struggles for product and tech leaders right now is to figure out where to apply AI in their existing product and business workflows. If you believe what you read online, AI is the cure for every problem you have. And yet, when it comes to deploying AI in production, most initiatives fail to meet the bar. A study quotes ‘88% of AI pilots fail to reach production’. According to another study by Gartner, “The survey found that, on average, only 48% of AI projects make it into production, and it takes 8 months to go from AI prototype to production.
This post is about providing the framework to help you assess and build deployment-ready AI products. But first, let’s talk about why AI pilots fail.
Why AI Pilots Fail
Suppose you launched a website for selling a software product (like Zendesk selling support software) worth 1000s of dollars. Since the cost of this software is high, you hired few sales people. You turned on the marketing campaigns and asked your sales team to start calling people who fill the interest form on the website.

What do you do when your website generates more form submissions (also known as leads) than your sales team can handle? Businesses have struggled with this question since long before websites came in. The sales team in the offline world used to identify and prioritise leads based on their likelihood to convert into paying customers. This way, they could get more ROI from their time.
We do a similar thing when it comes to website leads. We look at user profile data (how many employees, revenue, etc.), and their activities on website (clicks, time spent, etc.) to gauge interest. We have built AI models for lead scoring, which provide a high score for leads that have higher probability to convert. Salespeople are supposed to call leads with high scores only. You might mis-score some leads, but your productivity savings by not calling bottom x% can exceed the cost of mis-scoring.
While lead scoring works in many situations, it doesn’t work in situations where cost of mis-scoring > productivity savings. Now, this can happen in high stakes situations where software you are selling costs >$10,000. This can also happen in situations where the bottom x% that you are confidently rejecting isn’t high enough to get good productivity gains.
The above example shows how the same AI model that’s useful and reliable for one product can be problematic for another. So how do we classify which tasks to solve using AI, and in what way? Enters AI Capability Matrix.
AI Capability Matrix
AI Capability Matrix has 2 dimensions on which you have to evaluate every task — output verifiability, and task complexity. Let’s discuss them one-by-one:
Verifiable Output: Output verifiability means that either machine or humans can confirm the answer quickly, cheaply, and with high confidence. Addition of two numbers like 2+2 has a verifiable output (4). But predicting the features that will work for a particular product isn’t.
Complexity of Task: The second dimension is the complexity of the task. A more complex task is harder to perform. We define task complexity wrt human because it directly correlates to productivity gains. Classifying an email as spam vs non-spam is an easy task. Writing code to create an app is a hard task. So if the machine write code to create an app, it can lead to high productivity gains.

Before we apply this matrix, we need to separate high stakes vs low stakes tasks. A high stakes task is the one where the downside of mis-calculation is high. An example of a high stakes task is diagnosing critical illnesses. You can think of it as the 3rd dimension of the matrix, but for the ease of understanding and application, we will classify the tasks into high vs low stakes, and then apply the 2x2 on complexity and verifiability.
Low Stakes
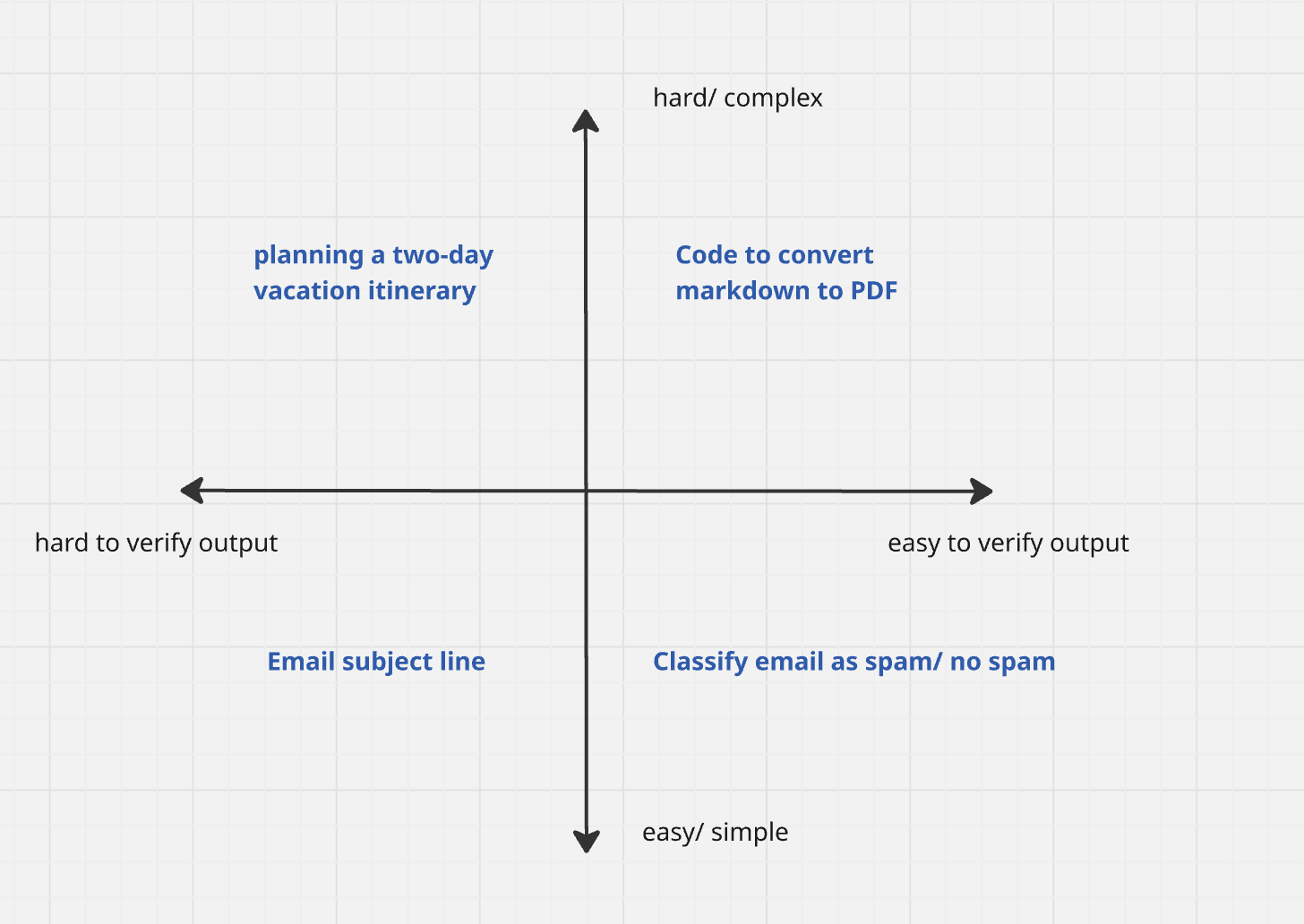
Let’s take some low stakes tasks that can be done by AI, and try to put them on the 2x2 matrix
Classify email as spam/ no spam: This is easy to do for humans, and easy to verify as well.

Code to convert markdown to PDF: This is hard to do for humans because they have to learn how to code, but easy to verify whether the conversion has gone well by just looking at the final output.
Writing email subject line: This is easy to do. However, it’s hard to verify if the email subject line will lead to higher open rate.
Planning a two-day vacation itinerary: Hard to do for humans since it’s time consuming. It is also hard to verify whether you have the most optimal plan without actually experiencing it. Since it’s a two-day trip, we have put it in low-stakes situation. A two-week trip with a toddler is what we can call a high-stakes situation.


How to Apply AI in Low Stakes Situations
Let’s talk about how to apply AI in these situations
Classify email as spam/ no spam - easy to do and easy to verify: Such tasks can be done by machines (Gmail does it for you) with occasional inputs from human evaluators to check if the AI model we built for this is working well.
Code to convert markdown to PDF - hard to do, easy to verify: Such tasks should be delegated to machines because they can lead to good gains. Let AI do the task, and put human to review the final output and accept.
Writing email subject line - easy to do, hard to verify: Using AI here can assist humans in reducing their cognitive load. So we can go for a maker-checker flow here. The AI creates a subject line, and humans verify and accept it. Below is what Copy.ai generated when given a prompt/ description — ‘email to newsletter subscribers on how to assess AI projects’

Planning a two-day vacation itinerary - hard to do, hard to verify: Humans need to spend a major amount of time redoing and verifying such tasks, so AI can get started on the task but co-piloting and verification is necessary throughout the task.



So by now, we have seen that even in the low stakes situation, the design choices of a product like a ‘Spam filter in Gmail’ can be significantly different from ‘Subject line generation in Copy.ai’ because one is easy to verify and the other isn’t. The major gain here is in situations which are hard/ complex for humans to do, but have an easily verifiable output. This is why single-click Landing Page Generators are all the craze :)
Let’s talk about high-stakes situations now.
High Stakes
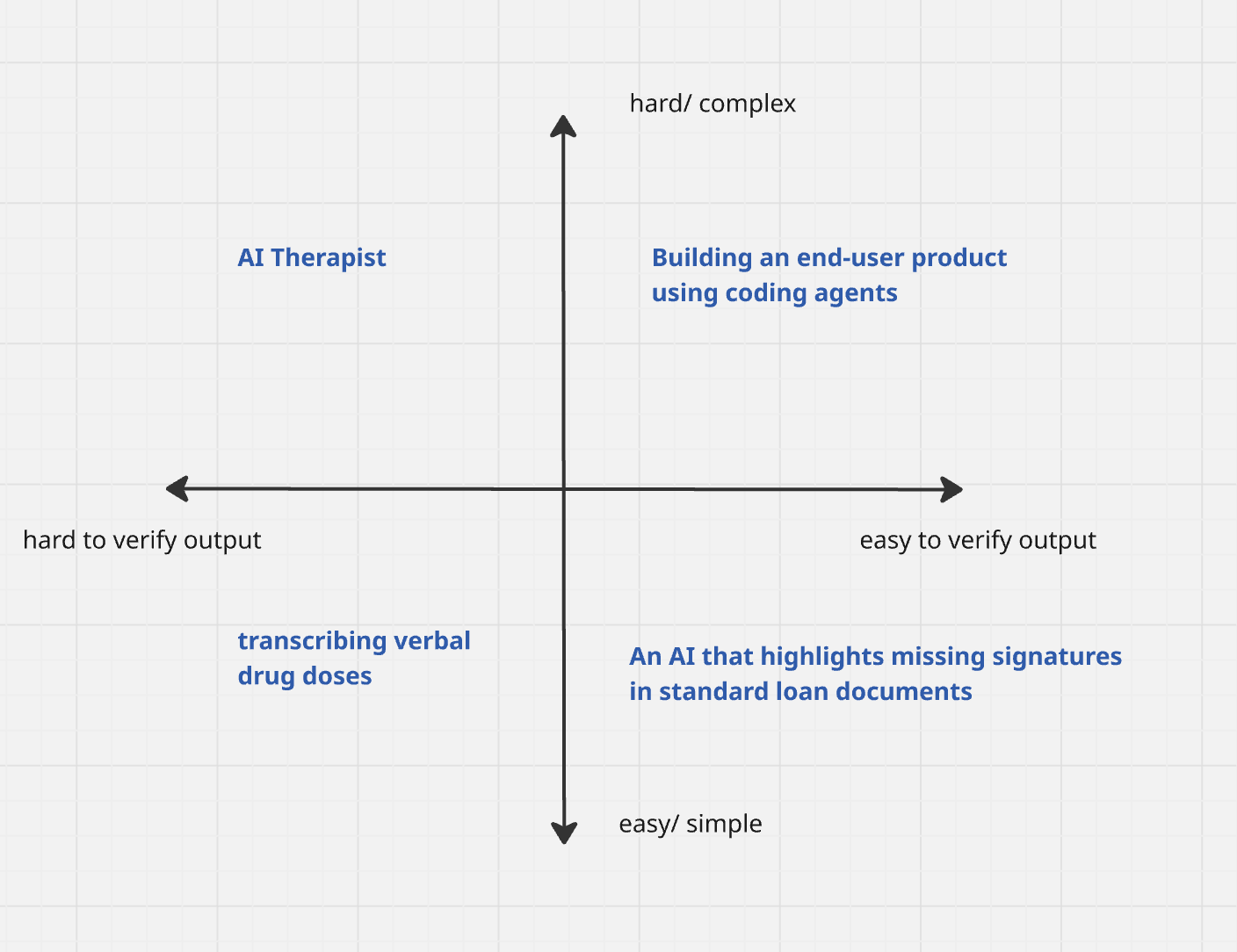
In high stakes situation, let’s cover each quadrant one-by-one
An AI that highlights missing signatures in standard loan documents: This is easy to do and easy to verify task. We need to always have a human-in-the-loop because a rejected loan due to absence of signature would affect an individual gravely, without a mistake of their own. Further, if the system passes a loan document that doesn’t have a signature, the company stands to lose in a dispute in future. Using AI here acts more like a 2-factor authentication, and reduces human errors.
Building an end-user MVP product using coding agents: This is hard-to-do and easy to verify. It can be tested easily by both humans and machines. Because it’s easily verifiable, you can get maximum productivity gains here by deploying AI. This use-case is so popular that we have a new name for it ‘vibe-coding’, thanks to Andrej Karpathy :)

AI Therapist: It’s hard to provide good advice as therapist. And it’s also hard to verify whether it’s the right advice for an individual. What makes it even harder to verify is that such transcripts are confidential. High stakes and hard to verify situations is where we should be highly skeptical of AI. It can only be used as an assistant to a professional, like an assistant to therapist but can’t work on it’s own even with some verification. Even if AI Therapist apps are working now for some, regulators are going to disallow such use-cases because of the inherent risk. We can see some studies coming around it already

Transcribing verbal drug doses: This is easy to do and hard to verify task since it’s hard for anyone else other than the doctor to catch a mistake in transcription. So such problems needs a multi-layered approach. AI transcribes it, but doctor has to review and sign it. Another example of this is Grammarly spelling-and-grammar check. Having such mistakes in high stakes situation like a book going out for print, or crucial emails can be problematic.

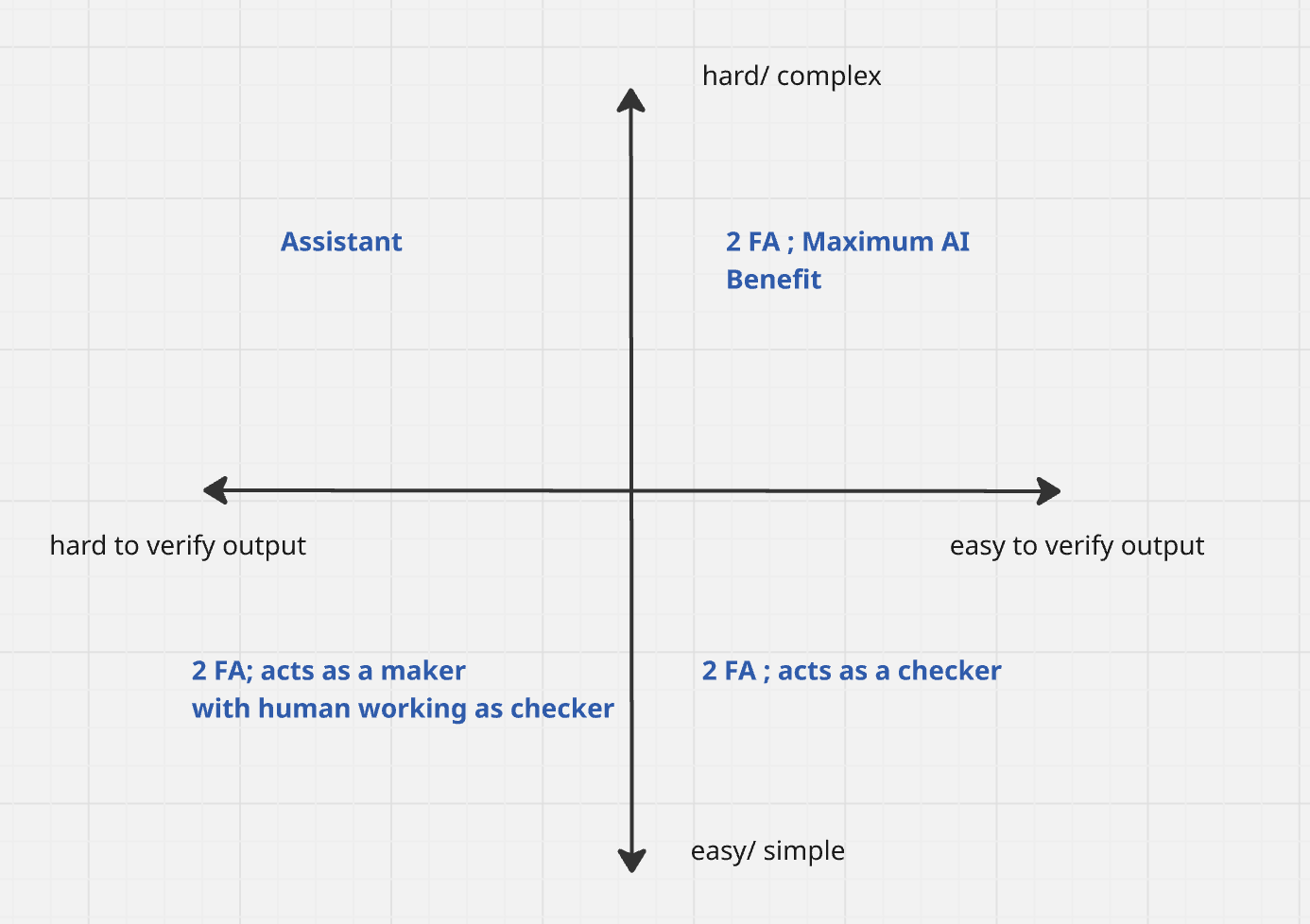
The entire matrix can be summed up as follows:
To summarise the recommendation, what we realise is that in high stakes situations, we need humans to either take a lead when verification is hard, or still verify as 2-factor authentication) when verification is easy.
Final Note
In both high stakes and low stakes situation, the tasks that easy to verify are being solved by AI. The reward is high in cases where the task is hard to do — multiple coding agents like Cursor, Replit, Copilot, etc. valued at $1-10B are a proof of this.
When it comes to tasks with no clear verification loop, AI does well in helping users reduce cognitive load by providing preliminary research. Like ChatGPT is a much better version of search, which helps people browse information across the Internet. AI can act as a great assistant when you have expertise in an area.
But when the stakes get high in unverifiable tasks, we should avoid relying on AI entirely since the downside is simply too high. A bad advise from LLMs in medical diagnosis can be disastrous.
The key takeaway here can be that many problems can be solved reliably if we deploy a human-in-the-loop. Some problems require an expert-in-the-loop as well. And few problems shouldn’t be solved by AI, even if AI provides a plausible solution there.
I hope the post helps you with some clarity on a topic most companies are struggling with.
If you are wondering how product management tasks fare on AI Capability Matrix, Subscribe to get the next post around it in your inbox!
Thanks,
Deepak