
How to Conduct Technical RCAs for PMs
+ Vibe-coding live session

👋 Hey, I am Deepak and welcome to another edition of my newsletter. I deep dive into topics around AI and product management. I run a live cohort-based course on AI product management as well. This post is an excerpt from that course. Applications for the course are now open for September Cohort.
16,000+ smart, curious folks have subscribed to the growth catalyst newsletter so far. To receive the newsletter weekly in your email, consider subscribing 👇
Let’s dive in the topic now!
RCA is short for root cause analysis. It is a structured analysis to find the root cause of a problem, and solutions to fix the root cause.
RCA problems are pretty similar to everyday problems that PMs face on the job. And that’s also a reason the technical PM interviews have started adding RCA problems in the problem-solving/ execution rounds.
RCAs can be both technical and non-technical. Here is a non-technical RCA,
“Imagine that you are a PM at Youtube, and you have seen the watch time going down by 20% yesterday. What would you do?”
A technical RCA would look like this:
“Imagine that you are a PM at Youtube, and you have seen the buffer time going up by 20% yesterday. What would you do?”
We would focus on technical RCA in this section! Understanding what it takes to conduct RCA gives PMs a deeper understanding of what engineers do when they face an issue.
Two Approaches to Conduct RCAs
When it comes to conducting RCA for an issue, there are two methods we can employ. The first one is taking a hypothesis-driven approach and the other one is going layer-by-layer to figure out what’s happening. Let’s talk about hypothesis-driven approaches first!
Hypothesis-Driven Approach
This approach starts by forming hypotheses (educated guess) about what might be causing the issue, then systematically testing each hypothesis.
Suppose that there is an increase in failures in the checkout flow for the CC payment method. In the hypothesis driven RCA, we map out possible reasons/ hypotheses for the failure. For example, the failures in the checkout process might be happening because of
a software bug in payment gateway integration
network timeouts
database connection failures
For each hypothesis, we need to get data/evidence that could prove or disprove it. For example, we can monitor network latency and # of timeouts to validate network timeouts hypothesis.
Layer-by-Layer Approach
This method systematically examines each layer of the system, from user interface down to the infrastructure. It's like peeling an onion where we examine one layer at a time to find where the problem originates.
For our checkout failure, we'd examine UI, application, service, DB, servers, etc. one by one to figure out where the problem originates from.
The key difference between these two approaches is their starting point. Hypothesis-driven starts with working hypotheses and works to prove/disprove them. Layer-by-layer methodically examines each component. So the obvious question arises – which one do we choose?
The better approach among these is usually situation dependent. We can use Hypothesis-driven RCA when we have a strong understanding of the system and the issue, and therefore have strong hypotheses. This approach is also time-efficient as compared to Layer-by-layer approach, so we should use it in time critical situations.
We can use the Layer-by-layer approach when we are new to the system and don’t have a good understanding of the system to figure out the initial hypothesis.
Many times, we combine both methods: we start with quick hypotheses to save time, and then fall back to Layer-by-layer analysis if initial hypotheses don't pan out.
So most of the time (especially interviews), hypothesis-driven RCA is what comes handy because this is where we start. Hypothesis driven RCA is also where PMs contribution can come in because of their understanding of system design and other external factors. So let’s look at how to do it in detail.
Hypothesis-Driven RCA
In the popular literature, one of the key approaches to do RCAs comes from the manufacturing industry, and is called 5 Whys.
The approach was developed by Japanese car manufacturers. The 5 Why method suggests you to keep asking ‘Why’ repeatedly to reach the root of the problem.
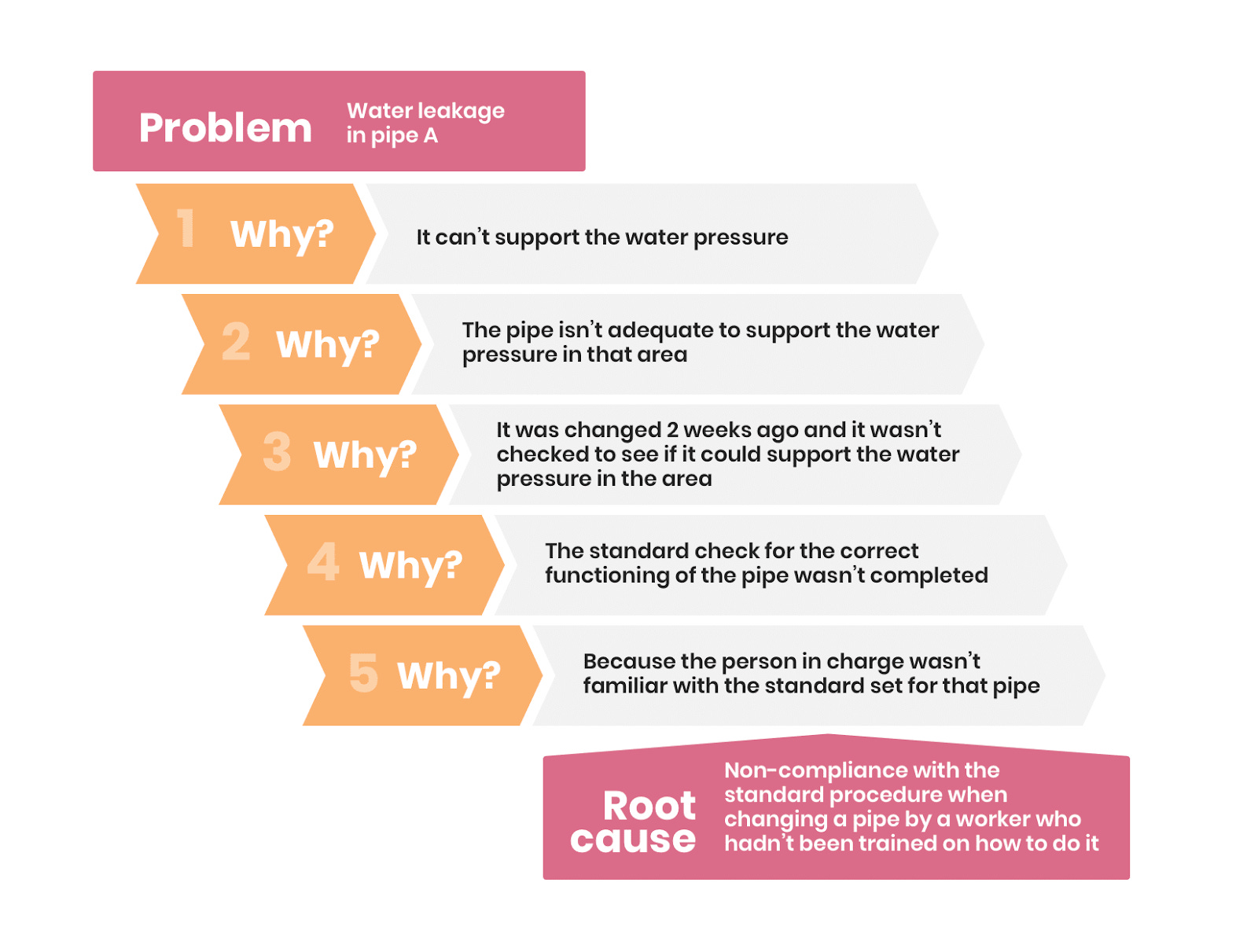
For example, assume that there is water leakage in pipe A. You can ask 5 Whys and see where it leads
Why is there water leakage in pipe A? → It can’t support the water pressure
Why can’t it support the water pressure? → The pipe isn’t adequate to support water pressure in the area. Note that different areas such as hilly vs planes can have different water pressure owing to their unique requirements.
Why isn’t it adequate to support water pressure in the area? → The pipe was changed 2 weeks ago and the pipe wasn’t checked to see if it could support pressure in the area
Why weren't the specifications checked? → The standard check for correct functioning wasn’t completed.
Why was the standard check not completed? → The worker changing the pipe wasn’t trained on how to do standard checks.
We now come to know that lack of training is the root cause of water leakage. Here is a visual representation of the same!
5 Whys is a pretty useful method in manufacturing processes because there is
Clear physical cause-and-effect
Direct access to people involved who observed the process
Visible physical evidence
All of this makes it easier to arrive at the root of Why the problem occurred.
But when it comes to solving technical RCAs, the approach doesn’t work that well because there are:
Complex interdependencies due to system design
Multiple parallel systems running concurrently that interact with each other
Lack of direct humans involved in the chain who have observed the process
Lack of physical evidence
And so 5 Why isn’t enough to do RCAs in case of technical failure. We need a new framework and that’s what we will discuss next.
Before we move ahead, quick announcement — I would be conducting a live session on ‘How to Vibe-Code in PM Interviews’ this Saturday. Please register for the Maven session if interested.
RCA Framework - CHASoL
To solve the technical RCAs, we would recommend you a 5-step process:
Step 1: Clarify the problem and its context (C)
Step 2: Generate plausible hypotheses (H)
Step 3: Get data to accept hypothesis to arrive at root cause (A)
Step 4: Suggest short-term solutions that would fix the issue immediately (So)
Step 5: Suggest long-term solutions to fix the root cause (L)
Let’s take a problem we started with, and see how it can be solved using CHASoL.
“Imagine that you are a PM at Youtube, and you have seen the buffer time going up by 20% yesterday. What would you do?”
Step 1: Clarify
Clarifying the problem and its context is the most important step of the RCA because it defines the boundaries of the issue.
To understand the problem well, we need to understand the keywords used in framing the problem, boundaries of the problem, and the broader context of the problem like its implications on users and business.
Let’s talk about keywords first. Do we understand what the buffer time means for Youtube, and how we are measuring it? Most of the time, PMs know these keywords well, but if you don’t, don’t hesitate to clarify them.
Clarifying the problem also involves defining boundaries of the problem. Suppose the interviewers (or your devs) tell you that the buffering problem is limited to Youtube long-videos. That will help you narrow down the hypotheses set.
Lastly, it’s important to talk about the implications of this problem, i.e. what it implies in terms of user experience, business, etc. Discussing implications goes on to show that you as a PM can look at the problem more strategically and prioritize.
For example, buffer time increase may lead to lesser watch time, which in turn can lead to lower ad revenue. So buffer time increase affects both business and users in a negative way. These implications can help the problem get prioritized quickly.
The last bit that can be useful to look at is the impact of the problem. Scale and severity are two components of the impact. Scale determines how much users or business is affected. A popular feature will have a higher scale. Severity determines how much worse the problem is. Multiplying these two gives us the overall impact of the problem.
In the above buffering problem, suppose that the buffering issue is happening in 20% of video plays. Further, buffer time is 10% of overall watch time (overall watch time is sum of actual watch time and buffer time), which means that if a user watches a 9-minute long video, they also get 1-minute buffer time. This makes the issue high severity since the impact of UX is pretty high.
So now, we have a buffering problem which is limited to Youtube long-form videos, and affects 20% of views. Further, it impacts UX severely. All of this knowledge makes it a high priority issue.
Let’s move on to the next step now!
Step 2: Hypotheses Generation
We discussed earlier that understanding the system design is essential to generate hypotheses.
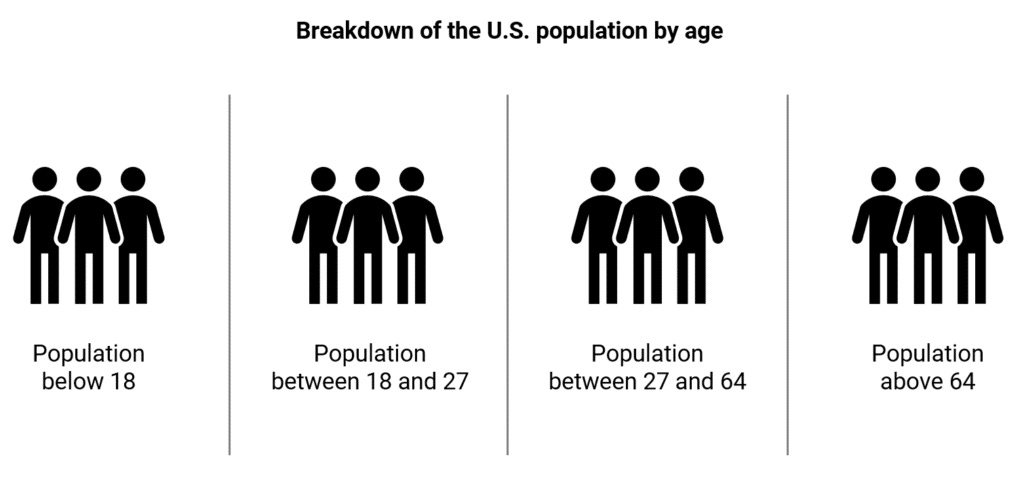
Along with system design, we also need a structured way to generate hypotheses so that we don’t miss any critical factor that could lead to an issue. MECE is a useful method for structured hypothesis generation. MECE stands for mutually exclusive, collectively exhaustive. It means covering all the factors exhaustively while also ensuring that these factors don’t overlap much with each other. Here is a good example of MECE where we break down the population by age. The groups are mutually exclusive, while collectively exhaustive.
As an example, while listing down the hypothesis for the Youtube buffer problem, we can say that it could be either an internal or an external issue. This sort of classification is MECE because
It covers all factors (internal + external) and is therefore exhaustive
The parts (internal, external) are also mutually exclusive.
To do RCA, MECE needs to be applied at multiple levels. This is where tree diagrams come in. Here is an example of a MECE tree diagram with two levels.
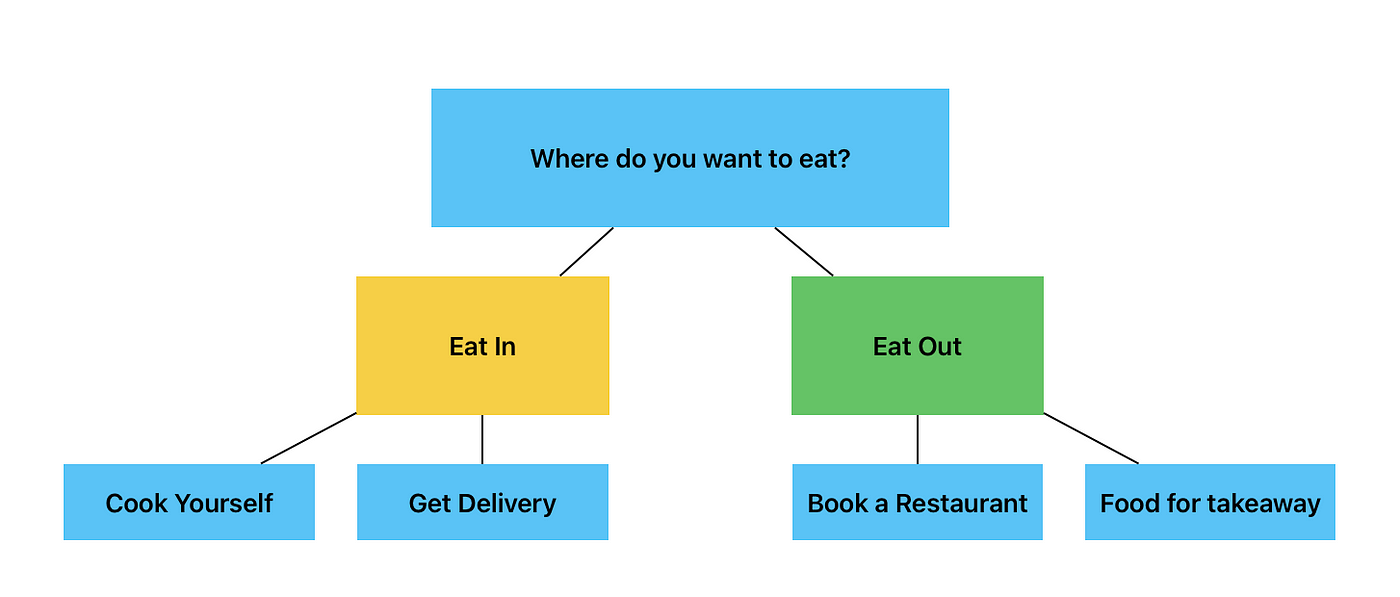
It’s called a tree diagram because it resembles a tree that can have two branches, and those branches can have multiple branches further. Tree diagrams help us break down the issue deeper without missing anything important.
Let’s apply system design and MECE to generate hypotheses for the Youtube video buffer problem.
MECE
We can start by saying that the issue could be because of internal or external factors.
Internal Factors: System Design
Buffering can happen because of any of these points in the system failing to deliver. The video request data flows from
User device → ISPs → CDNs
If the video isn’t available in the CDN, the request can go from
CDNs → load balancers → Youtube servers (Ads + Video)
Post request processing, the data flows backward. The issue could be at any point of the system in that flow as well.
The internal factors could be related to
App issues (say a bug that got introduced due to recent app/web release)
Infrastructure issues like issues with CDNs, load balancers or servers (Ads + Video)
Configuration issues
External factors: The external factors could be
User device, browser, or OS causing problems
Issue with ISPs
Local networks like mobile data providers not working properly
Step 3: Accepting/ Rejecting Hypotheses
To validate hypotheses, we need to look at the right data that helps us select or reject a particular hypothesis.
We need to look at three sets of data while validating hypotheses:
Strong correlation between an event related to hypothesis (an internal event like app release, or an external event like sudden traffic surge) and the issue
Do metrics that we are logging support the hypothesis?
Let’s look at hypotheses one by one and accept/reject them. We will use brackets to provide answers to help us understand whether to accept or reject the hypothesis.
App issues
Have we done a recent release that coincides with the buffer issues? (Yes, we looked at the deployment logs, and noticed that a new major app update was rolled out yesterday on mobile. The timing broadly matches when the buffer time starts increasing)
Do metrics that we are logging support the hypothesis? (We can next look at the buffer time of other app versions yesterday. These versions would be available on user devices who didn’t have the latest version. Suppose we don’t find a buffer issue on those versions, we can be almost sure that this is the likely cause. Next, we have to just go through the checklist to ensure there aren't any additional problems)
Infrastructure issues
Have we made any changes in the infrastructure layer that coincides with the buffer issues? (No)
Have we seen any metric uptick/downtick in the infra monitoring dashboard? Specifically, have we seen a significant traffic spike because it can lead to buffering problems. Or have we seen any other abnormalities in the CDNs, load balancers, or server metrics? (No, we can reject this hypothesis)
Configuration issues
Have we made any changes in the config that coincides with the buffer issues? (No, we can reject this hypothesis)
User device, browser, or OS
Is there a user device, browser, or OS where this problem is worse? (No, except we have seen this buffer time increase on mobile devices only which supports the app update hypothesis)
ISPs and Local Networks
ISPs are local to certain geographies. Have we seen this problem concentrated in certain regions? (No, we can reject this hypothesis)
ROOT CAUSE: By now, we have confirmed that the mobile app update introduced the issue. We asked the team what it was about and got to know that we had changed the video pre-loading logic for long-form videos. Video pre-loading logic is essentially the logic using which a video player loads a portion of the video content before it's actually played. We can further see the logs to check when exactly the buffer time is increasing in a user session. We find that it happens at the beginning of the video.
Step 4: Solutioning
In real-life product development, we tend to figure out how to resolve the issue immediately first. We should do that when we talk about the solution in interviews as well.
Immediate actions here would be to roll back the mobile app update
Step 5: Long-term Solutions
Long-term solutions would focus on how to avoid this problem entirely:
Implement stricter performance testing before the release
Monitoring for buffer time anomalies
Implement staged rollouts so that the impact isn’t very high on UX
Further Reads: Real-World Issues and How Teams Solved Them
So now that you have understood RCAs well, where do you go next? You can read and understand real-world issues if you would like. Learning about real-world issues helps you in two ways. First, it builds the confidence that you can understand real-world RCAs well. Second, it expands your knowledge around technical vulnerabilities which over time can help you avoid these for your own products.
Rather than creating a simplified write-up, I would like you to go directly to the blogs written by the teams at companies like Meta, Stripe, Netflix and read them. Use AI and the internet to understand what you don’t. Afterall, no one understands every technical term/issue on the planet, not even the best engineers.
Meta, 2021
When Facebook experienced its massive outage in October 2021, it wasn't just Facebook that went dark - all of its family of apps including WhatsApp, Instagram, and Oculus became inaccessible simultaneously. This six-hour outage affected billions of users globally and cost the company approximately $100 million in lost revenue. The scale and severity were unprecedented, with a complete service unavailability across all platforms.
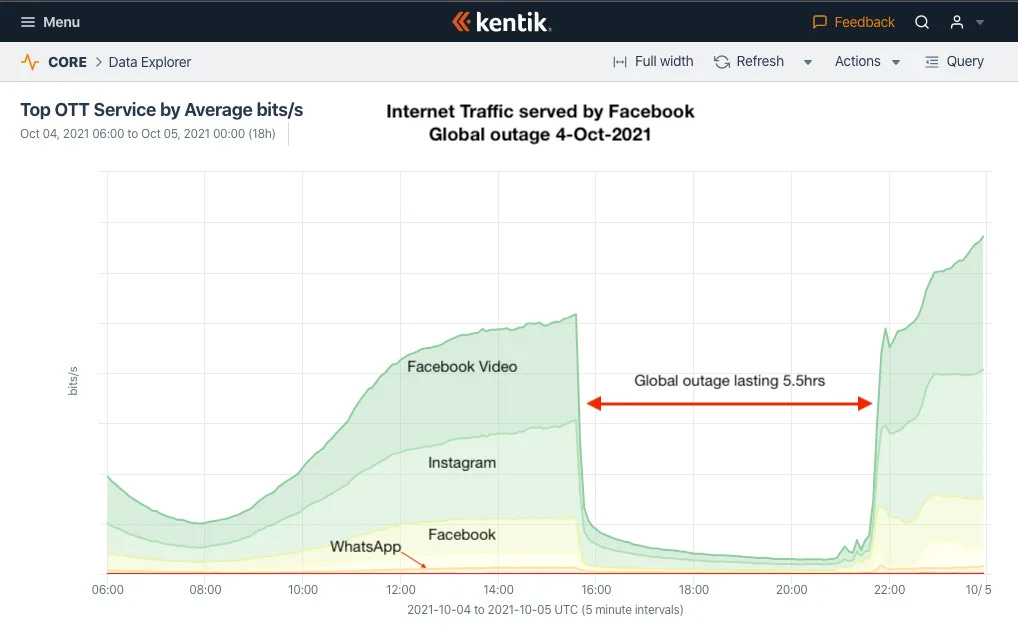
A good way to gauge how far you have come in doing RCAs is to read their blog and see how well you can understand it -
Update about the October 4th outage - Engineering at Meta
Stripe, 2019
On 2019-07-10 from 16:35 to 17:02 UTC, and again from 21:14 to 22:47 UTC, the Stripe API was severely degraded. A substantial majority of API requests during these windows failed.
Here is an RCA written by the Stripe team. Go through it and see for yourself how a well-written RCA looks like:
https://stripe.com/in/rcas/2019-07-10
Netflix, 2012
On Christmas Eve 2012, Netflix's streaming service went down for customers across the Americas for about 12 hours. The timing was particularly problematic as it occurred during what is typically one of their highest-usage periods.
Here is an RCA written by the Netflix team. It is a good example of what an infra failure looks like:
A Closer Look at the Christmas Eve Outage | by Netflix Technology Blog
This would be all about conducting RCAs. As mentioned earlier, this is an excerpt from one of the modules of ‘Advanced Tech and AI program’ I run. Applications are now open for September Cohort. Do check it out!
Thanks,
Deepak